Jet-Nemotron
高效语言模型的革命性突破
通过创新的PostNAS框架和JetBlock技术,Jet-Nemotron实现了与全注意力模型相当的精度, 同时在生成吞吐量上提升高达53.6倍, 在预填充速度上提升6.1倍。 这是大语言模型效率优化的重要里程碑。
PostNAS框架
创新的神经架构搜索管道,从预训练的全注意力模型开始,
冻结MLP权重,高效探索注意力块设计。相比传统方法显著降低架构搜索成本,
避免了从头开始训练的巨大开销。
混合注意力架构
精心设计的全注意力、滑动窗口注意力和线性注意力组合。
在保持高精度的同时将计算复杂度从O(n²)优化到O(n),
大幅提升长文本处理效率。
JetBlock技术
全新的线性注意力块设计,采用动态因果卷积核和核生成器。
相比静态卷积具有更强的适应性,能够根据输入动态调整特征提取模式,
同时移除冗余操作提升效率。
硬件感知优化
针对特定硬件平台进行架构搜索和参数优化,确保在实际部署环境中获得最佳性能表现。
通过批处理优化和KV缓存管理,
最大化GPU利用率和吞吐量。
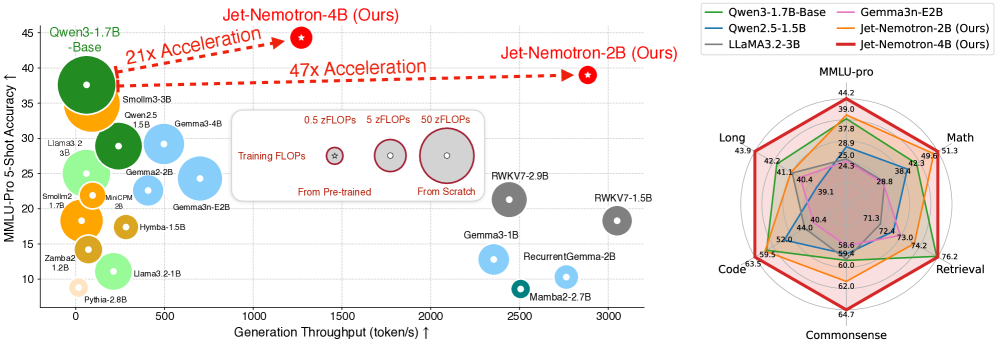
Jet-Nemotron与最先进高效语言模型的性能对比 - 在H100 GPU上64K上下文长度下的测试结果
53.6×
生成吞吐量提升
6.1×
预填充速度提升
47×
相比Qwen3性能提升
59.6%
MMLU准确率
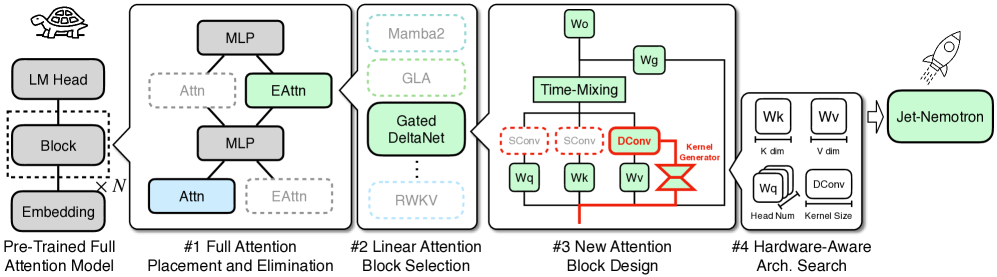
PostNAS技术路线图 - 从预训练模型开始的粗到精架构搜索流程
1
全注意力层放置和消除
使用once-for-all超网络自动学习最优的全注意力层位置。
这一步骤显著优于传统的均匀放置策略,在保持关键任务精度的同时减少计算开销。
通过智能放置,模型能够在最关键的位置保留全注意力机制。
2
线性注意力块选择
系统性评估现有线性注意力机制,在准确性、训练效率和推理速度之间找到最优平衡点。
避免了传统方法依赖小型代理任务的局限性,确保搜索结果能够直接转化为最终模型的性能提升。
3
JetBlock创新设计
引入动态因果卷积核生成器,实现基于输入条件的自适应特征提取。
相比传统静态卷积,JetBlock能够根据不同输入动态调整卷积核参数,
同时移除Query和Key上的冗余静态卷积操作。
4
硬件感知架构搜索
考虑实际硬件约束进行超参数优化,确保模型在目标部署环境中达到最佳性能表现。
通过调整批处理大小、chunk大小等参数,最大化GPU内存利用率和计算吞吐量。
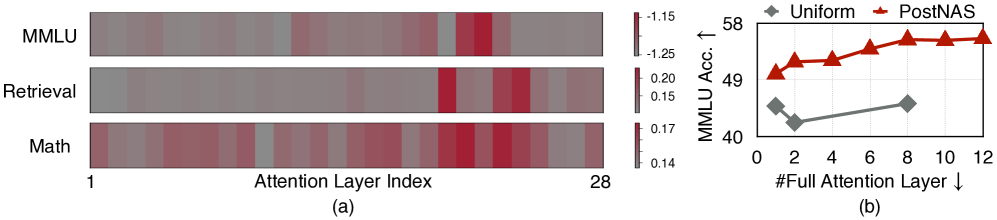
在Qwen2.5-1.5B上的层放置搜索结果 - 展示PostNAS如何智能选择全注意力层位置
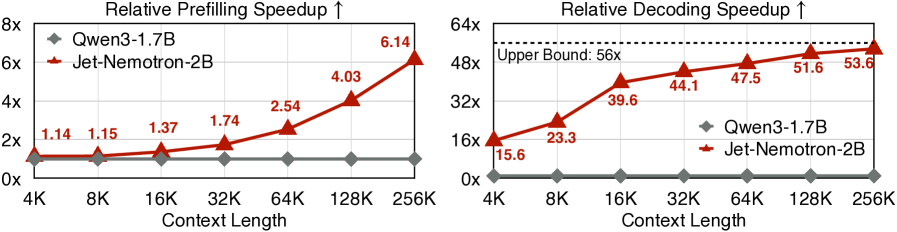
不同上下文长度下的效率对比 - Jet-Nemotron在长文本处理中展现出显著优势
核心创新总结
Jet-Nemotron的成功源于系统性的架构优化:
从PostNAS框架的高效搜索,到JetBlock的动态卷积设计,
再到硬件感知的部署优化。这种端到端的优化策略确保了模型在保持高精度的同时,
实现了前所未有的推理效率提升。
实际应用价值
相比传统全注意力模型,Jet-Nemotron在边缘设备上也表现优异:
在Jetson Orin上实现8.84×速度提升,在RTX 3090上实现6.50×速度提升。
这为大语言模型的广泛部署和实际应用奠定了重要基础。